データ品質のことを調べていたら、名寄せにたどり着いた。
データマネジメントの中でもごく小さなテーマではあるものの、実際問題、ぶれっぶれなデータをどう処理するか、具体的な方針とアクションを立てられないと解決しない。
調べてみると、代表的なツールのいくつかはSFAやCRMで、その一機能として名寄せが実装されているようだ。まあそうだよね。一方で、その場合にデータレイクやデータウェアハウスに様々なデータがあるときにどうするんだ?という話になる。
名寄せ特化で見てみると、いくつか出てくる。Precisely Trillium, Data Quality Services(SQL Server), OpenRefine, etc.
入力元+ETLで名寄せしたり、DBで名寄せしたり、クライアントアプリで名寄せしたりとなかなかにバラッバラである。あと、データ品質マネジメントの観点で言えば、Informatica Cloud Data Qualityでも名寄せできそうだ。
名寄せでできることは、どのツールも割と同じように見える。結局は、人間的に見て「これ一緒だね」を一緒にしてくれる。それがルールベースなのかAIなのか手段はいろいろあれど。
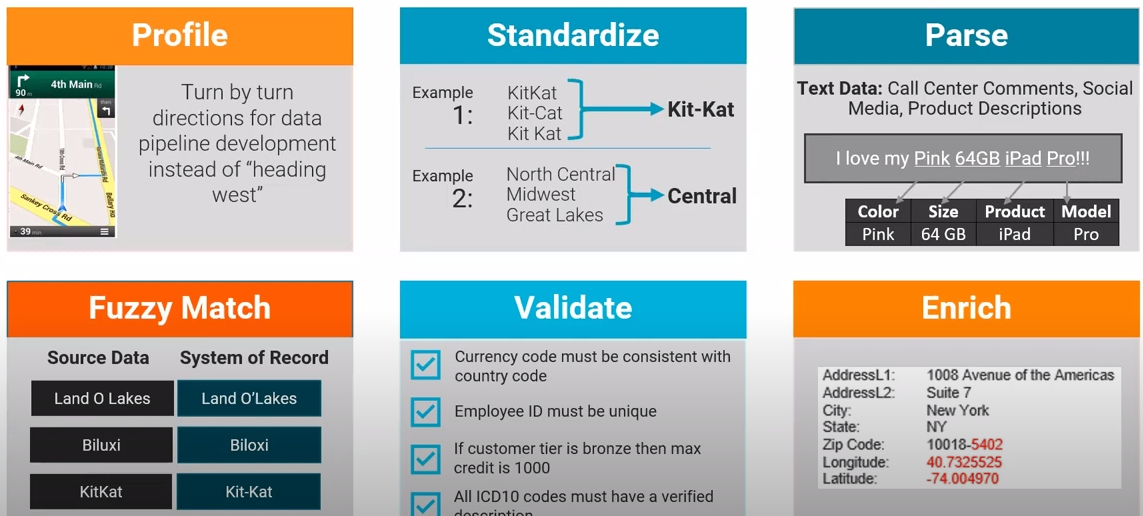
出所:https://www.youtube.com/watch?v=nGB9hbtb-_s
この名寄せという局所的な課題に対して、目先の対処はたとえばOpenRefineを使うのはいいかもしれないが、全社的なデータマネジメントで考えるなら名寄せツールというよりはデータ品質ソリューションが適切だろう。
では、データ品質ソリューションでは名寄せの他にどういったことをしてくれるんだろう。ChatGPT先輩に話を聞いた。
データプロファイリング
データ品質ルールの定義と適用
データ品質の監視と報告
データクレンジング
データマッチングおよびデデュプリケーション
データ品質の自動改善とトリガー
メタデータ管理
データアクセスとセキュリティ
おお、それっぽい。
大体何となく想像はできるけど、ちなみにデータプロファイリングって結局何やるの?
どうやら、データの構造情報を取得したり(RDBであれば主キー、型とか)、データに対して統計解析を行ったり(平均値、分散などなど)、欠損値をチェックしたり、データからパターンを読み取ったり、データ間の関連性を読み解いたりしてくれることらしい。
超絶ざっくり、完全に理解した。
こんな感じで、今後もゆるく調べてみる。