最近の AI
自分自身,AI が専門ではないため知識としては薄っぺらいものの,ChatGPT を日常的に使うようになり AI には何が出来て何が出来ないかがなんとなく感覚的に分かってきた.
昨今の AI 技術の進歩は凄まじく,特に文章・動画像・音声の生成系は品質・パフォーマンス共にものすごい勢いで改善されている.
ちょっと考えればそれは間違いであると分かることではあるが,ChatGPT があたかも本物の人間のように振る舞えてしまうが故に,”最近の AI” はなんでもできるんだ,と世見に勘違いされてしまっているようにも見える.
実際,GPT モデルは対話に特化するようファインチューニングされている LLM(=自然言語処理モデル)であるから,文章生成・質問応答・情報抽出あたりが一番得意であるはずだが,簡単な計算問題なんかは普通に正解を出してくる.多少難しい大学入試レベルの問題でも,順序立てて説明するようプロンプトを与えれば,論理的に問題を ”解いているような” 振る舞いをし,結果的に正しい答えを導き出せる.
でも,やっぱり奴ら(AI に対する3人称は奴らで良いのだろうか)の本業は ”文章生成” であるから,それらしく説明しているけど内容はめちゃくちゃ,なんてことも結構ある.それでも文章として正しく体裁を保っていれば,それは奴らにとってちゃんと仕事をしたことになる.
機械と人間のインタフェース
「機械語」と言われるくらい,機械が認識できる言語(?)と人間が普段使っている言語には大きな違いがある.
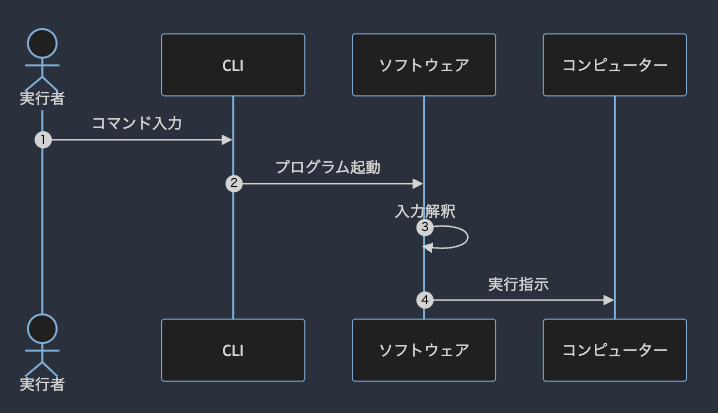
人間が作ったモノであるにも関わらず,機械は自然言語をこれまで読み書きすることは出来なかった.だから人間は機械のためにコンパイラを作ったり,できるだけ機械語に近い(もしくは機械語に変換しやすい)プログラミング言語を発明して習得したり,プログラムを動作させるときは,CLI からコマンドを入力したりしてきた.
例えば,コンピューターにこんな命令をしたいとする:
A.txt というファイルをコピーし,B.txt というファイル名で保存せよ
これを,Bash を使って命令する際は以下のように入力し実行する:
cp A.txt B.txt
cp は copy の略だろうということが分かれば,なんとなく人間にも理解できるコマンドではあるが,それでもやはり人間が使う言語よりかはいくらか無機質であるように感じる.英語にすれば
Copy A.txt as B.txt
であるけど,日本語にすれば
A.txt を B.txt としてコピーしてください
となる.
英語を主言語とする人々からしたら直感的にわかりやすいコマンドかもしれないが,日本語しか知らない人々からすれば,やはり ”機械に合わせる” 意識は強いのではないだろうか.
このように,従来のコンピューター操作は,人間が機械に合わせることで実現されてきた.
そこで現れたのが視覚的なインタフェース,いわゆる GUI というやつである.
GUI は画面上にボタンやテキストボックスを並べて,人間が直感的にコンピューターを操作しやすくしたものである.
先程の例に関して言えば,
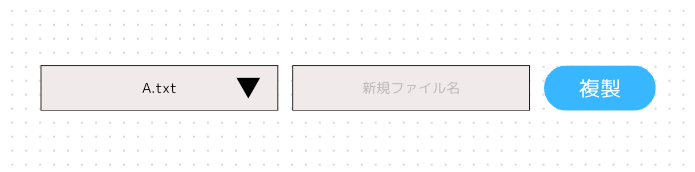
こんな GUI を用意し,
cp $before $after
のように,コマンドの入力を変数とすることで,小難しいコマンドを入力しなくても直感的にコンピューターを操作することができるようになる.
これを仕事にしているのがソフトウェアエンジニアとかいう人達である.
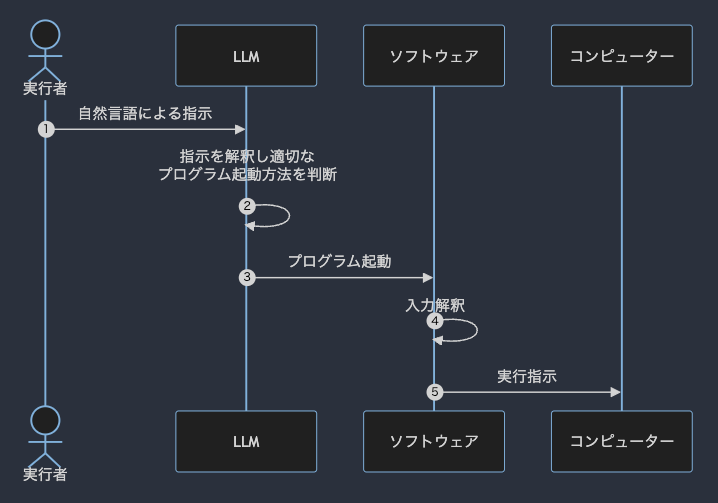
しかしながら,昨今の AI 事情を外から眺めていると,UI としての LLM(LLM as UI)という考え方はありなのではないか?と考えることがある.
LLM as UI
LLM という言葉が適切なのかはちょっと微妙なところではあるが,要は「人間の言葉を人間の言葉として理解できる奴らをインタフェース(特に入力)に使えないか?」ということである.
従来のコンピューターは,人間が使う自然言語を上手く解釈することができなかった.したがって人間が機械に合わせる CLI か,人間と機械を視覚的にリンクさせる GUI を使って機械を操作していた.
GUI は直感的で操作しやすいが,基本的に目が見える前提で作られているし,ユーザーには使いやすいデザインを求められるし,操作する端末サイズによってレイアウトを調整するよう設計しなければならない.
もちろん,CLI も目が見えなければ操作はしずらいことに変わりないのだけれど,CLI と GUI をグラフィカルであるかどうかという観点で評価をすれば, CLI にグラフィカルな要素はほとんどないため(最近は CLI でも対話モードで操作できるものが増えてきたので一概には言えないけど),音声操作のしやすさで言えば,CLI のほうが操作しやすいだろう.
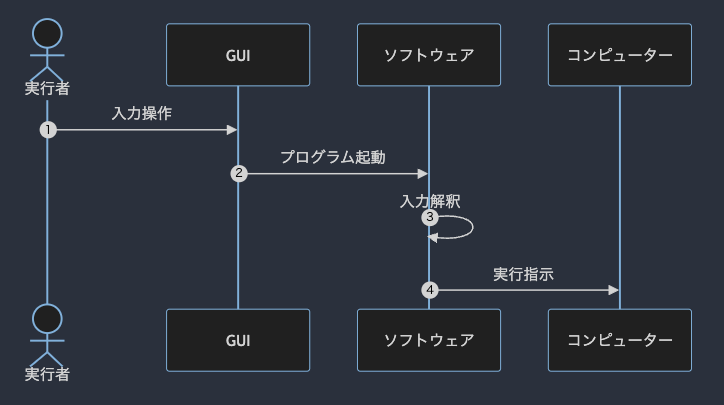
一方,LLM as UI はどうか.
人間が「こうしたい」と思ったことをそのまま口にすれば(入力すれば),LLM がよしなに解釈しプログラムを操作する.
これに近しい技術がスマートスピーカーだろうか.
例えば Alexa なんかは.「Alexa,音楽をかけて」と話しかければ音楽を流すし,家電と連携させておけば「Alexa,電気を消して」と話しかけることで家の電気を消すことができる.
しかしながら,スマートスピーカーはまだまだ命令の解釈能力が低く,所定の音声コマンドにしか反応できないし,こちらの意図を汲み取った柔軟な対応はできない.
me: アレクサ,今日の気温は5度を下回る?
Alexa: 現在の天気は快晴で,気温は 15 度です.今晩の予想最低気温は 0 度です.
おそらく,「気温」「下回る」などの単語から,ユーザーの関心が「気温が低いかどうか」であると推論され,Alexa は今日の最低気温を答えるのだと思うが,ここでユーザーが欲しい回答は「はい,今日は20時頃に5度を下回り0度になると予想されます」である.
これをあらゆるソフトウェアでできるようになる時代がくるのではないか?
現代のスマートフォンのホーム画面にはアプリのアイコンがたくさん並んでいて,アプリを開くとメニューやボタンが配置されている.それが全てなくなり,ちょっとした物理ボタンと小さな液晶だけになる.
イメージとしては...

うーん,革新的な見た目ではないが,要はこういうこと.笑
とは言え,スマホの機能には視覚的なインタフェースが必須なものがたくさんある.
例えばゲーム,カメラ(写真やビデオの閲覧),動画視聴.
ゲームは音声コントロールよりも物理的に指で操作するものが多いしそれは需要として無くならないだろう.
動画や写真は,高解像度で大画面であることが結局求められる.
ここが,スマートグラスやスマートコンタクトレンズに代替されれば,操作は音声で事足りるということはあるかもしれない.
結論,未来のデバイスは以下のようになると妄想している:
映像の出力はスマートグラスなどのウェアラブル端末
音声の出力はイヤホン(日常的に身につけるものであれば,骨伝導が主流になるかも)
音声・映像の入力(マイクとカメラ)もスマートグラスに内蔵
ゲームなど,物理的な操作が必要な場合のみアタッチメントとして無線接続できるコントロールパッドを持ち運ぶ
こちらは映像を出力する必要がないため,大きさとしてはスマホの半分くらいのサイズで,ベゼルレスな ipod nano みたいなやつ.ソフトウェア側のコントロールで好きなようにボタンなどを配置できる.ようは Nintendo DS の下の画面.
ただし,昨今の MR デバイスのように,スマートグラスに投影された映像にも仮想的に触れられることは重要で, Web ページのスワイプなどは指で出来たほうが便利だとは思う
パフォーマンス?
生成 AI は,莫大な情報を含んでいることもあり動作するのに大層な環境を要求してくるイメージがある.現に,ChatGPT のようなものをその辺で売っているノート PC で動かすことは到底不可能.
最近だと,StreamDiffusion など処理が高速化されたソリューションなども出てきてはいるが,モバイル端末でサクサク動作するようになるまでには少々時間がかかるかもしれない.
生成 AI ではないが,最近は CSS にまで機械学習が使われる時代となった:
このように,軽量な機械学習モデルが随所に散りばめられるような時代なのだから,画面からボタンが消えて代わりに AI が出てきてもおかしくないわけである.