目標
基本的には以下の論文の内容を世の中にある日本語のデータセットで再現しつつ、より改善していきたい。
Instructor Text Embedding (instructor-embedding.github.io)
今回の実験内容
学習に使うプロンプトをタスクごとに1つに固定する
ノイズになってるかもしれないしね。
利用するモデル
モデルに関してはoshizo/sbert-jsnli-luke-japanese-base-liteを利用してファインチューニングしている。
利用したデータセット一覧
JNLI(文ペア分類)
JSICK(文ペア分類)
JSTS(文ペア分類)
MARC-ja(文章分類)
JaQuAD(QA)
JSQuAD(QA)
xlsum(要約)
ner-wikipedia-dataset(固有表現抽出)
加工後の学習データのサンプル数の分布
JNLI: 20073
MARC-ja: 363371
JSICK: 4500
JSTS: 12457
JaQuAD: 31984
JSQuAD: 27533
tydiqa-goldp: 1436
ner-wikipedia-dataset: 20766
実験結果
ベースライン(oshizo/sbert-jsnli-luke-japanese-base-lite)
JSTS、JSICKについてはそのまま正解のスコアと予測した類似度のスピアマンの順位相関係数を求めて評価している。
JNLIは-1<類似度<-0.5のときはcontradiction、-0.5<類似度<0.5のときはneutral、0.5<類似度<1のときはentailmentと判定して、多クラス分類問題として基本的な評価指標をいろいろ出している。
前回との差分としては、MARC-jaは分類モデルとしての評価を出すようにしています。
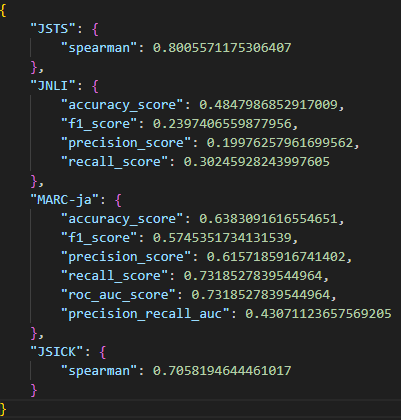
前回の結果

今回の結果
よくわからないけど性能悪化した…。

軽い考察
プロンプトは固定しない方が良いということなのかもしれない。
次のアクション案
データセットの追加
分類+マルチラベル+QAタスクのデータセット
ネガティブのサンプル(label=-1.0)のデータを精度高く増やす手段を何か考える(特にハードネガティブを増やしたい)
MARC-jaもうちょい減らす
現状ラベルが同じもの同士の組み合わせのケースで文章のAとBの組み合わせとBとAの組み合わせを別の組み合わせとして認識してしまっていて重複が許可されてしまっているのでその重複を削除する。
独自のデータセットを作るための仕組みを作って継続的に精度を出していく。