目標
基本的には以下の論文の内容を世の中にある日本語のデータセットで再現しつつ、より改善していきたい。
Instructor Text Embedding (instructor-embedding.github.io)
今回の実験内容
MARC-ja、JaQuAD、JSQuADのサンプル数が多すぎるので減らした
sentence1同士とsentence2同士の類似度を用いたスコアが一番高いものすべて採用していたので、それを類似度が0.8以上とか0.8以下とかの閾値を指定してノイズをなるべく減らすようにしてみた。
利用するモデル
モデルに関してはoshizo/sbert-jsnli-luke-japanese-base-liteを利用してファインチューニングしている。
利用したデータセット一覧
JNLI(文ペア分類)
JSICK(文ペア分類)
JSTS(文ペア分類)
MARC-ja(文章分類)
JaQuAD(QA)
JSQuAD(QA)
加工後の学習データのサンプル数の分布
JNLI: 20073
MARC-ja: 562584->550899
若干減っただけや…
JSICK: 4500
JSTS: 12457
JaQuAD: 31984
良い感じに減った気がする
JSQuAD: 1000
なんかめっちゃ少ないのでバグ臭い
実験結果
ベースライン(oshizo/sbert-jsnli-luke-japanese-base-lite)
JSTS、JSICKについてはそのまま正解のスコアと予測した類似度のスピアマンの順位相関係数を求めて評価している。
JNLIは-1<類似度<-0.5のときはcontradiction、-0.5<類似度<0.5のときはneutral、0.5<類似度<1のときはentailmentと判定して、多クラス分類問題として基本的な評価指標をいろいろ出している。
前回との差分としては、MARC-jaは分類モデルとしての評価を出すようにしています。
前回の結果

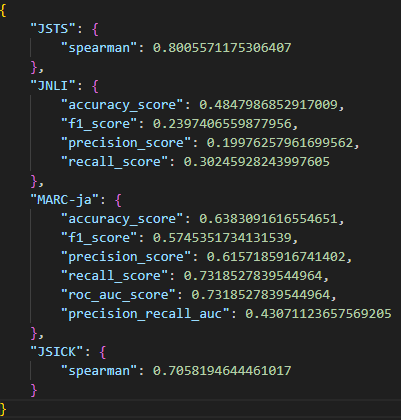
今回の結果
今回からテスト用のデータセットのカウントを評価結果のJSONに含めることにした。
前回との比較をしてみると、JNLI以外は性能が改善している。MARC-jaに関しては学習時のデータ量が減っているが、性能が改善している。

軽い考察
MARC-jaでいうと、前半と後半でポジティブ・ネガティブが異なるケースが一番うまく対処できていない印象。次に批判が書いていたときに製品に対するレビューか対象なのか正しく判断できていなさそう。とりあえず文章の中にネガティブ表現あるからみたいな雑な感じ。
JSTSはそもそも類似度が低くなっていないのが気になる。-0.3が一番類似度低い状態なので、何か工夫が必要そう。
MARC-jaの思いっきりネガティブをポジティブと勘違いしちゃったパターン
{"sentence1": "次の製品のレビュー文のポジティブ・ネガティブの分類の役に立つベクトルを表現してください。購入して1ヵ月程。熱暴走ですぐに落ちていたノートが全く落ちていません。一番冷やして欲しいバッテリー部分にきちんと風が当たります。これの前に使用していたものは、同価格帯の製品でしたけど、風が当たっていたのはPC本体の中央部。熱くなるのはそこではありませんでした。PCの熱でファンが変形していき、どんどん性能が落ちていきましたし。ファンの交換も可能なこの製品は長く使えることを期待します。ノートPCの買い替えも検討していただけに、この安定感は助かっています。使う人を選ぶ製品だと思いますよ。大きいですし、うるさいですし。調整は出来ますけど、当然速度を落として静かにすれば冷却能力は低くなります。気休め程度、あるいは、念のためという方はもうちょっと静かなタイプにしておくほうがおすすめです。販売元の商品紹介を見ても、日本仕様はアダプターは別売と書いてありますが、届いたものには変換アダプターが入っていました。用意するのは確認してからのほうがいいかもしれません。", "sentence2": "製品のレビュー文の内容がポジティブ", "label": -1, "predicted_similarity": 0.9979188442230225}
「この安定感は助かっています」、「おすすめです」などの字面だけみればポジティブに見えるが、全体的な印象みたいなところは拾えてなさそう
{"sentence1": "次の製品のレビュー文のポジティブ・ネガティブの分類の役に立つベクトルを表現してください。こんな実話があったことはとても凄い事だが映画 と思えばそこまで熱くなりませんでした最後の方は少しハラハラするシーンがありたした眠くはならないですみて損はないが友達には薦めない作品", "sentence2": "製品のレビュー文の内容がポジティブ", "label": -1, "predicted_similarity": 0.9611146450042725}
「みて損はない」というあたりはポジティブに捉えちゃいそうだけど、遠回しなネガティブな表現が多めなのでOut of domainだったのかも
{"sentence1": "次の製品のレビュー文のポジティブ・ネガティブの分類の役に立つベクトルを表現してください。Amazon.comに「10枚のうち5枚が44.1K、16bitのHDCDで収録されている。残りの5枚も音質が格段に向上している」とのカスタマーレビューがあったため実際に購入して確認してみた。HDCDで収録されていたのはSong to a Seagull、Clouds、 Ladies of the Canyon、 Blue、 Don Juan's Reckless Daughterの5枚。この5枚に関しては確かに既発のCDよりも音圧が高くなっている。ただしきちんとリマスタリングされた印象はなく音圧のみをいじったという感じ。またボックスにもCD自体にもHDCDのロゴはない。残りの5枚に関しては特に音質の向上は感じられなかった。", "sentence2": "製品のレビュー文の内容がポジティブ", "label": -1, "predicted_similarity": 0.9448657035827637}
前半ポジティブ、後半ネガティブがわからなかったっぽい
逆にポジティブなのに思いっきりポジティブと勘違いパターン
{"sentence1": "次の製品のレビュー文のポジティブ・ネガティブの分類の役に立つベクトルを表現してください。感動したい人には良いと思う。 このロボットは次々とオプションを取り付けて、一生懸命自己実現しているが、死をもって人間とするなら今までのオプション何なんだよ。実際、目が見えなかったり、耳が聞こえなかったり、味がわからなかったりする人達も立派な人間なんだから、別にいらないだろ。ロボットのくせに人の女も盗るわ、結構むちゃくちゃやってると思う。自我に目覚めたロボットはロクなことしないと相場が決まっているが、こいつは『ターミネーター』のスカイネットや『ブレードランナー』のレプリカントよりも、ある意味タチが悪い。 しかしこの映画で一番人間らしいのは、やはり、ロボットに婚約者を寝取られたあのアゴ兄さんだろう。人間らしいを通り越して、むしろ、いとおしい。僕はこの人が気になってこのロボットのことなんてどうでもよくなった。裁判を起こす権利が一番あるのは、ロボットではなくて、この人だろう。だが、相手がロボットゆえに裁判すらできないという悲しさ。アゴ兄さんはその後きっと人間的に成長したはず。頑張ってロボットになったかもしれない。", "sentence2": "製品のレビュー文の内容がポジティブ", "label": 1, "predicted_similarity": -0.9634483456611633}
映画の中のキャラへの批判に反応している?
{"sentence1": "次の製品のレビュー文のポジティブ・ネガティブの分類の役に立つベクトルを表現してください。 長年ビートルズを聴いていて、一番理解(解釈)できないアルバムです。子供の頃、家にあった赤盤、青盤を聞いてビートルズを好きになり、お小遣いをためて初めて買ったアルバムでしたがあまりにも子供(小学生)には難解でした。今でもそう感じます。何でこんなに評価が高いんだろうと思っていたけど、ひとつの回答が「言葉の壁」が大きいなって・・・。多くのビートルズ関連の著書にあるように、英語本来のニュアンスはネイティブじゃない日本人にとっては理解できません。よって、日本人はこのアルバムの本来の良さは理解できないんだろうなって。海外の方が俳句を理解することは難しいようにね。でも「ビートルズであれば全て良し」の馬鹿丸出しで5つ星。音楽性が高いと思うよ。⑦曲目なんか大好きです。最後の曲なんか小学生の私が理解出来なくても簡単にぶっ飛ぶことは出来ましたから。70年代ロックを聞いている方や、その他ビートルズのアルバムを聴いてから手にとってほしいな。", "sentence2": "製品のレビュー文の内容がポジティブ", "label": 1, "predicted_similarity": -0.916581392288208}
「理解できません」とか「子供(小学生)には難解でした」あたりが製品への批判ととってしまっていそう
{"sentence1": "次の製品のレビュー文のポジティブ・ネガティブの分類の役に立つベクトルを表現してください。本編の映画自体は、前2作と比較した場合かなりパワーが落ちている感じがしました。大がかりな割に笑えない、ちょっとした笑いをとるべきところでイマイチ笑えない。くっだらねぇ、ってのは全然OKなのですが、前作までは金をかけてくっだらねぇ事をやって笑いを取り、シンプルながら手の込んだ事をやって笑いをとってたんだけど、そういうシーンはかなり減ったかなぁ、という印象です。併せて、パロディにしているのもなかなかわかりにくく、普通の人にはそういう楽しみ方はなかなか難しいです。いろいろあって多少内容の変更があったからかもしれないけれど、ちょと苦しいかなぁ...とはいえ、映画そのものも十分に楽しめるレベルだと思います。で、さらに映画が終わった後の特典映像は見る価値があります。新キャラクタ紹介やメイキング、カットされたシーン集など、非常にオースティンパワーズ・ファン向けによく出来ていると思います。こっちだけでもシリーズのファンなら見る価値は十分にある気がします。映画だけなら★3つでも甘い気がしますが、特典を併せてDVDとしてはで★4つをつけておきます。", "sentence2": "製品のレビュー文の内容がポジティブ", "label": 1, "predicted_similarity": -0.974129319190979}
前半厳しい意見からの後半のポジティブに反応できていなさそう。
JSTSの最小予測類似度のデータ
{"sentence1": "次の文の意味をベクトルで表現してください。黄色いボンネットバスが停車しています。", "sentence2": "次の文の意味をベクトルで表現してください。赤い消火栓の奥にオレンジ色の球体が見えます。", "label": -1.0, "predicted_similarity": -0.3179318904876709}
次のアクション案
データセットの追加
ネガティブのサンプル(label=-1.0)のデータを精度高く増やす手段を何か考える(特にハードネガティブを増やしたい)
MARC-jaもうちょい減らす
各レビュー文+positiveのときに「製品のレビュー文の内容がポジティブ」、negativeのときに「製品のレビュー文の内容がネガティブ」というケースもペアの類似度使ってなんとかして減らしたい