ディスプレイが地震で壊れたので実験が止まってました。
目標
基本的には以下の論文の内容を世の中にある日本語のデータセットで再現しつつ、より改善していきたい。
Instructor Text Embedding (instructor-embedding.github.io)
今回の実験内容
NERのデータセット
NERの対象のテキストの全文とNER後の単語のEmbeddingの類似度が近くなるようにする。
例えば、以下のような感じ
対象のテキスト: 「トヨタ自動車はプリウスの販売をしている」
NER後の単語: 「トヨタ自動車」、「プリウス」
ポジティブサンプル
{"text1":"トヨタ自動車はプリウスの販売をしている",text2: "トヨタ自動車", label: "1"}
ネガティブサンプル
{"text1":"トヨタ自動車はプリウスの販売をしている",text2: "ホンダ", label: "-1"}
文章中に含まれている単語にオーバーフィットしそうな気はしてうまくいかなそうな気はするが、ダメもとで一応やってみた
利用するモデル
モデルに関してはoshizo/sbert-jsnli-luke-japanese-base-liteを利用してファインチューニングしている。
利用したデータセット一覧
JNLI(文ペア分類)
JSICK(文ペア分類)
JSTS(文ペア分類)
MARC-ja(文章分類)
JaQuAD(QA)
JSQuAD(QA)
xlsum(要約)
ner-wikipedia-dataset(固有表現抽出)
加工後の学習データのサンプル数の分布
JNLI: 20073
MARC-ja: 363371
JSICK: 4500
JSTS: 12457
JaQuAD: 31984
JSQuAD: 27533
tydiqa-goldp: 1436
ner-wikipedia-dataset: 20766
実験結果
ベースライン(oshizo/sbert-jsnli-luke-japanese-base-lite)
JSTS、JSICKについてはそのまま正解のスコアと予測した類似度のスピアマンの順位相関係数を求めて評価している。
JNLIは-1<類似度<-0.5のときはcontradiction、-0.5<類似度<0.5のときはneutral、0.5<類似度<1のときはentailmentと判定して、多クラス分類問題として基本的な評価指標をいろいろ出している。
前回との差分としては、MARC-jaは分類モデルとしての評価を出すようにしています。
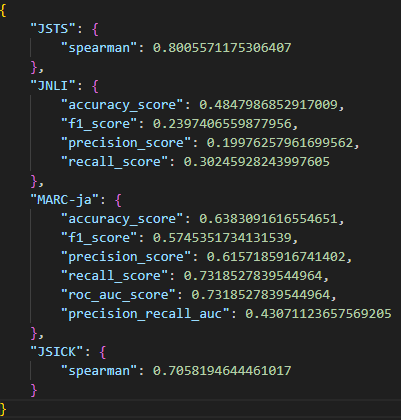
前回の結果

今回の結果
前回と似たり寄ったりで誤差なレベルに見えてきた。JSTSはさらに悪化している。

軽い考察
スコアの低いJNLIを見てみると、まあ確かによくわからない感じにはなってる。
{"type": "JNLI", "sentence1": "[仮説]次の仮説の文章を前提の文章と比較したとき含意、矛盾、中立の含意関係認識に使いやすいベクトルで表現してください。キリンが木々のあいだから顔を出しています。", "sentence2": "[前提]次の前提の文章を仮説の文章と比較したとき含意、矛盾、中立の含意関係認識に使いやすいベクトルで表現してください。キリンが、木の中から首を出しています。", "label": 1.0, "predicted_similarity": 0.4613127112388611}
{ "type": "JNLI", "sentence1": "[仮説]次の仮説の文章を前提の文章と比較したとき含意、矛盾、中立の含意関係認識に使いやすいベクトルで表現してください。双翼プロペラの飛行機が駐機しています。", "sentence2": "[前提]次の前提の文章を仮説の文章と比較したとき含意、矛盾、中立の含意関係認識に使いやすいベクトルで表現してください。空港に、1機の飛行機が停まっています。", "label": 0.0, "predicted_similarity": 0.331565260887146}
ふと思ったけど、「One Embedder, Any Task: Instruction-Finetuned Text Embeddings」の論文でプロンプトをタスクごとに同じものを使って埋め込みベクトルを作成していて、ランダムで生成するみたいなことをしていないのには理由がある気がしてきた。T5も図だけ見ると入力のプロンプト部分は固定っぽいし。
自分の場合はランダムでプロンプトを与えることで推論時にいろんな表現でも同様のEmbeddingをつけてほしいと思っていたが、実用上はテンプレート的に使えれば良いので固定の方が良い気がしてきた。やるにしてももっといろんな表現のパターンを作るべきで今のところタスクごとに8種類程度なので量が少ないすぎて意味ないどころか学習のノイズになっていそう。
次のアクション案
データセットの追加
分類+マルチラベル+QAタスクのデータセット
ネガティブのサンプル(label=-1.0)のデータを精度高く増やす手段を何か考える(特にハードネガティブを増やしたい)
MARC-jaもうちょい減らす
現状ラベルが同じもの同士の組み合わせのケースで文章のAとBの組み合わせとBとAの組み合わせを別の組み合わせとして認識してしまっていて重複が許可されてしまっているのでその重複を削除する。
プロンプトを固定するのを試す。
独自のデータセットを作るための仕組みを作って継続的に精度を出していく。