エンジニアは17人。
2025年は、チームとして機能開発やデリバリーに集中することができた1年だった。Go や Cloud に関する技術基盤の変化が小さく安定していたことが大きい。
改善面は、主にサーバ費用の削減、AI と多人数開発を前提とした制約の追加、内部ライブラリの品質向上に取り組んだ。
2024年と比較すると技術基盤の大きな変更は少なく、基盤が安定してきたことがわかる。代わりに2025年は、完成度を上げるための詳細な改善が増加した。
改善の加速
Stackでは、専門の Enabling チームや Platform チームを設けていないため、構造的に改善を進めにくい環境にある。それでも開発と並行して積極的に改善に取り組んでくれるメンバーが増え、新たな視点からの改善が進んだ。
ドキュメント
これまでチームで管理するドキュメントは、品質や効果を安定させることが難しいと考えており、チームでのドキュメント管理は最低限に留めていた。 具体的には「書いたが誰にも読まれず、気づかないうちに更新されなくなり古くなる」といった状況は起こりやすい。
しかし AI の登場により、ドキュメントは「人が気がついたら読むもの」から「AI が常に読むもの」へと変化した。 ドキュメントが更新されていなければ AI が正しく動かないため、自然と改善の動機付けが生まれる。また、AI がドキュメントレビューを行ってくれる点も大きい。
このようにドキュメントのフィードバックループが機能し始めたことで、適用範囲を少しずつ検討・拡大している。
コーディングエージェント
コーディングエージェント の普及によって、フロー効率が上がり、リードタイムが短くなったかは判断が難しいが、品質が向上したことは間違いない。
またドキュメントの話のように、これまで運用コストが高く実現できなかった施策が現実的になった。
また着手までの心理的ハードルが高かったタスクを着手しやすくなった。具体的には、CI や Lint の整備、一括置換では対応できない大規模なリファクタリングなどがある。
改善内容
Go 1.22
reflect.TypeOf から reflect.TypeFor[T] へ移行
Go 1.24
t.Context()
go runからgo toolへ移行
Go 1.25
synctest で flaky なユニットテストを改善
modernize の実行
https://pkg.go.dev/golang.org/x/tools/go/analysis/passes/modernize
Google Cloud の ID Token パッケージの移行
https://pkg.go.dev/google.golang.org/api/idtoken
↓
https://pkg.go.dev/cloud.google.com/go/auth/credentials/idtoken
Spanner パーサの移行
spansql から memefish へ移行
xerrors パッケージの削除
xerrors を利用していたが独自実装に変更した。 インターフェースは Go 標準の errors パッケージとほぼ同等で %w でエラーをラップすることができる。差分は、スタックトレース取得用の関数がある点のみである。
多くの非公式 error 系パッケージはリッチな機能を持つが、それらの機能は errors パッケージではなく、独自の Error 型として実装する方針とした。これによりerrors パッケージとの差分を最小限に抑えつつ、様々な機能を使うことができる。
Cloud Trace へのエクスポート停止
費用が高いためCloud Trace へのエクスポートを停止した。 サンプリングも検討したが、メンバーへの確認の結果、TraceID を付与し Cloud Logging からトレースを追跡できれば十分という結論になった。
gqlgen / gqlgenc の omitzero 対応
GraphQL において null と undefined を区別できるようになった。
Shopify APIはnull と undefinedで挙動が異なるものが存在する。
null → nullで更新
undefined → 何もしない
gqlgenのgoField directiveのtypeによるfieldごとのtype binding
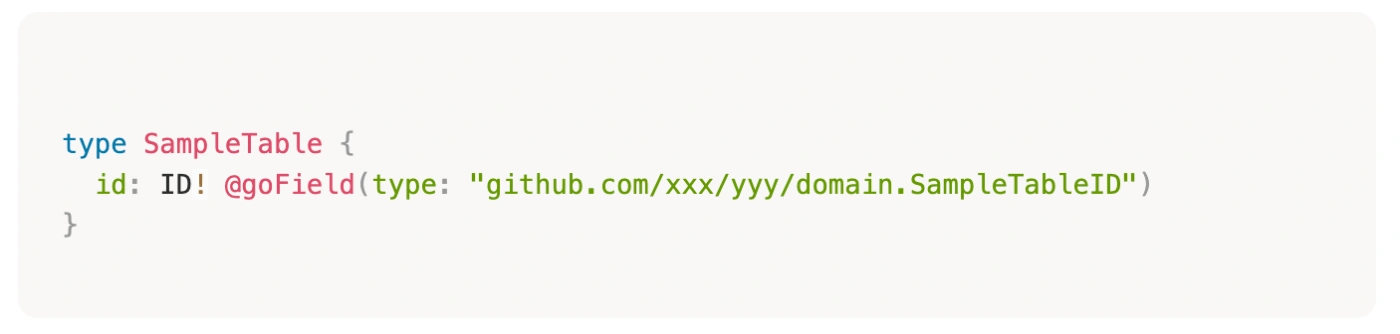
GraphQLはID型を利用するが、domainではテーブルごとにIDを用意している。この場合は、コード上でID型とdomainのテーブル固有のID型の間で変換が必要になるが、goFieldのtypeフィールドを利用することで不要になる。
AI 向け Go スニペット集の整備
AI が古い Go バージョンのコードを書くことがあるため、専用のスニペット集を整備した。
CI による Spanner マイグレーションの下位互換性の警告
マイグレーションに下位互換性がないことによる不具合は、E2E テストでは検知できないため、CI で警告を出すようにした。
Cloud Tasks の事前条件違反によるリトライ方法の変更
非同期処理において、他の処理が完了していないなどの事前条件違反が発生した場合、これまではエラーを返して Cloud Tasks にリトライさせていた。
しかし、大量にエラーが発生すると Cloud Tasks がキューのレート制限を行い、通常タスクの実行速度が低下する問題があった。そこで、事前条件違反時にはエラーを返さず、改めてタスクをキューに追加する方式に変更した。
非同期処理のシーケンス全体を表示するコマンドの用意
Pull Request の Body に、当該 Pull Request で変更したユースケースからの非同期シーケンス全体を自動的に記載するようにした。これにより、レビュー時に影響範囲を把握しやすくなった。
Error Report の整備
状況によっては、エラーメッセージが正しくレポートされないことがあった。 Google Cloud の Error Report は機能面で不足があり、運用を安定して回すためには手間がかかる。Google Cloud には、Observability の延長として、Error Report にももう少し注力してもらいたいと感じている。
Dataflow Primeへ移行
SpannerのChange Streamを使っている関係でDataflowを使っている。リリース時に念の為強めのスペックでリリースしたが、費用がかかっていた。ある日Googleから動的にスペックを変更できるDataflow Primeへの移行の案内が来たため移行を実施することにした。
これは株式会社DELTA様に検証と移行を実施して頂きました。
Cloud Run の設定管理を Terraform から YAML に変更
宣言的な Terraform と命令的な Cloud Run のデプロイは相性が非常に悪いため、Terraform で Cloud Run を管理しない方針とした。
バックエンドの E2E テスト(API テスト)をより本番環境に近づける
これまでは、テストから直接 Usecase 関数を実行しているケースもあったが、API の呼び出しや Cloud Storage へのファイル配置など、本番と同等のトリガーを起点としてテストを実行するように変更した。
E2E テストごとの環境変数設定の改善
複数のテストケースが同一の Google Cloud プロジェクトを利用しているため、E2E テスト環境ではテストごとに環境変数を切り替える必要がある。
これまでは、テスト時の HTTP リクエストヘッダーに環境変数を設定し、context に埋め込んでいた。しかし、この方法では非同期処理の先まで値を伝播させる実装コストが高かった。
そこで、環境変数を DB に保存し、middleware で DB から読み込んだ環境変数を context に埋め込む方式に変更した。
GitHub Actions runner を blacksmith へ移行
https://x.com/sonatard/status/1945493761049673744
CI の自動リトライ
デプロイや Lint のタイムアウトなどは自動リトライするようにした。 また、E2E も一部 flaky であるため、自動リトライを導入した。
domain の最大数を定義
商品あたりのバリエーション数の最大値
const ProductVariantLimitPerProduct = 100
domain に最大値を定義することを徹底するため、Lint を作成した。この値を Spanner のクエリの LIMIT に設定する。
これにより、実装者がクエリ実行時に想定している最大レコード数をどのように考えているかがコード上で表現されることになる。その結果、レビュアーが実装者の意図をレビューしやすくなり、想定外のデータ量によってメモリが圧迫される問題を減らすことができる。また、実装から仕様としてリレーションが読み取れる効果も大きい。
一般的には、リレーション数の仕様は ER 図などで記載することが多いが、ER 図とは異なり、実装に情報があることで「必ずその実装で動いていること」が保証される点は大きなメリットである。
domain の GoDoc の記載ルール
引数、戻り値、事前条件、事後条件を記載する。
domain を宣言的に書くための Claude Code のルールを整備
基本的には、usecase も domain も、上から順番に関数を 1 つずつ実行するだけの実装になっていることが理想である。 for ループの中で複数の条件分岐や処理がある実装は黄色信号。
octocov によるカバレッジ計測
domain と lib の package は、カバレッジが低下すると CI が落ちるようにした。30% から開始し、現在は 60% まで向上している。
これも、AI により積極的に実施可能になった施策の1つである。テスト対象関数の GoDoc に事前条件や事後条件を書くことで、AI は人間よりも適切に境界値テストを実施してくれる。
ユニットテストの書き方を統一
テーブルドリブンテスト、want 構造体、fields 構造体、args 構造体、cmpopts.AnyError、cmp.Diff を利用する。 gotests によるテストのテンプレート化、CLAUDE.md の整備。
Usecase 関数の GoDoc に冪等性の有無を書くことをルール化
冪等性が保証されていない実装は、リリース後にバグが発覚しやすい。しかし、Usecase の冪等性をチームで意識して実装することは難しく、効果的な対応を見いだせずにいた。
AI の登場により状況が変わり、GoDoc に冪等性の有無とその理由を書くことで AI がレビューしてくれるようになった。また、実際には冪等性の有無も AI が記載するため、その過程で AI が問題点に気づいてくれる。冪等性の記載は必ず行わなければ効果が発揮されないため、Lint で記載を必須化している。
理想的には、API テストで同じパラメータを用いて 2 回実行するテストをすべての API に対して書くことだが、現時点では必須化までは考えていない。
Gemini Code Assist によるコードレビュー
ケアレスミスの大幅な削減と、コードレビューコストの大幅な低減につながった。 今年一番の改善は、間違いなく Gemini Code Assist だった。
GitHub の Pull Request に背景の記載をルール化
「現状」「現状のままでは困ること」「実装内容」の記載を必須にした。背景の記載がない場合は CI が落ちるようにしている。
これにより、レビュアーが内容を理解しやすくなり、より適切なレビューが可能になった。この情報は AI のレビュー精度向上にもつながる。
また1つのPull Requestで異なる複数の変更をすることの低減にも繋がる。背景には1つの変更の説明だけを書くスペースがあるため、もしコード上で複数の変更をしていると背景の説明と関係ない変更となり矛盾が生まれる。
またPull Request作成者は、他人がわかるように背景を論理的に記載することで、自分が実装した内容の検証としても機能する。
E2E テストの作成単位をルール化
これまではテストサイズに関するルールがなかったが「1 つのテスト観点につき 1 つのテストを作成する」方針にした。
SQのE2E テストは 757 ケースとなった。
Claude Code の導入
Rules、Skills を整備した。
Lint の作成
Uasecase関数からUsecase関数を呼ぶことを禁止
Usecaseから環境変数にアクセスすることを禁止
UsecaseからPubSubをPublishすることを禁止
domainのID周りの実装ルール
冗長な Type Parameter を検出 (gopls を利用)
Cloud TasksのQueue名の長さ上限
GraphQL の description の記載確認
Webとバックエンドの整合性
Spanner関連の実装制約 9個
諦めたもの
GOCACHEPROG を設定し、Cloud Storage に Go のビルドキャッシュを保存
単純にこれを実施するだけでは高速化しなかった。
Cloud Run Worker Pool を利用した GitHub Actions self-hosted runner
スケールダウンで苦戦した。今後、self-hosted runner に新しいリリースがあるようなので期待している。
反省編
SaaS 部分の API サーバの DB と企業依存 API サーバの DB を分離
StackのSQ はエンタープライズ向けサービスであり、企業の既存システムとの接続は必須となる。そのため、SaaS 部分の API サーバと企業固有の API サーバを用意しているが、これまで DB は分離していなかった。
基本的には、DB に限らずシステムは安易に分けるべきではないという思想で運用してきたが、サーバを分けた時点で DB も分けておくべきだったと後悔している。これは過去で一番大きな自分の意思決定の失敗と言えるだろう。
現在分けないことで問題があるというわけではないが、新たな企業のサーバを作るときには、DBを分離するという意思決定をした。そうなると既存の分離していないDBだけがシステム構成として歪になるため、保守コストの増加が予測できる。とうい点でミスだったと言える。
結果としては、開発と並行しながら 2 か月で分離を完了してもらえたため、大きなダメージにはならず、本当に助かった。
decimalのOptional対応
Goでdecimalを扱うために https://github.com/shopspring/decimal を利用している。しかしこのパッケージが持つDecimal型はSpannerに対応していないため、Decimal型をラップする独自のDecimal型を定義していた。
その後DecimalをOptionalで保存するために、decimal型にIsNullフィールドを追加する変更が行われた。
また年月が経ち、enumをOptionalで保存するケースがでてきたが、SpannerのGo SDKの問題で独自定義したstringの型をポインタとしてSpannerに保存できない。ここでもDecimalと同じ対応が行われた。
しかし今の実装だと、型からOptionalなのかどうかが判定できない問題がある。これは別のタスクをしていて気がついた。
この時点で、修正するべきだと判断して、合計4つの型のOptional対応とType Paramaterを利用した汎用的なOptionalの実装を2週間かけて終えた。
Decimal型の実装は以前から見ていたはずで、それでも「型からOptionalなのかどうかが判定できないから治すべきだ」と判断できなかったことが最大のミスだ。
また修正作業中に気がついたことだが、Optionalが必要な箇所はとても少なく、Optionalの箇所だけ対応していれば影響範囲の小さい変更だったはずだが、根本的な型がIsNullフィールドを持っているため、広範囲に影響してしまう変更になってしまったことも反省点の1つだ。
課題
ユニットテスト、E2E テスト、ドキュメントの拡充により、現在理解している仕様の範囲、かつ最新状態でのバックエンドの品質は高い状態を維持している。
一方で、現在でも障害が発生することはあり、以下のような課題が残っている。
仕様漏れ
本番データを考慮した下位互換性、適切なDBスキーママイグレーション
CIによる警告である程度改善を期待したい
本番データを考慮した下位互換性、適切なDBデータマイグレーション
バッチの実装ミスに気がつくことが困難
想定外の副作用がある
Spannerのフルスキャンによるパフォーマンスの低下
Web やアプリの動作確認、テスト
アプリのテストは進めてもらっているため状況改善に期待