DensePoseなどのCSMの学習についていろいろ論文を調査しました。
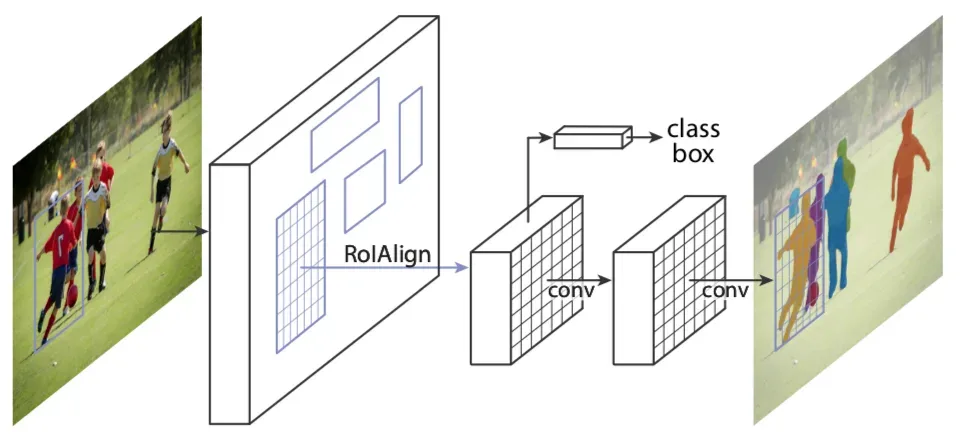
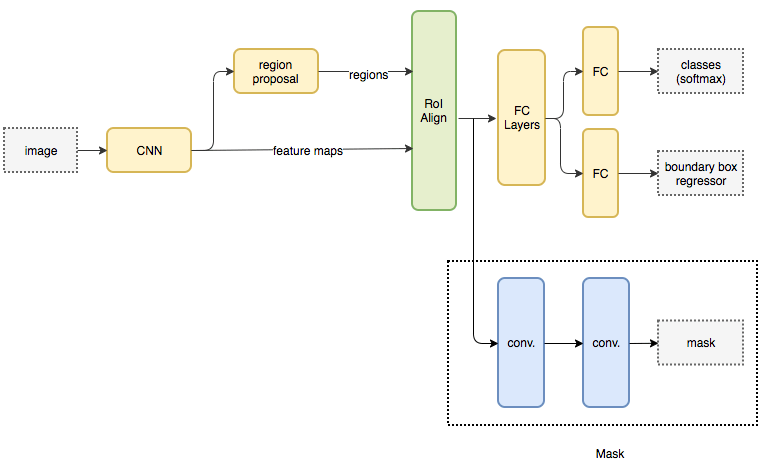
-[1] Mask R-CNN https://blog.negativemind.com/2019/04/27/general-object-detection-and-instance-segmentation-mask-r-cnn/
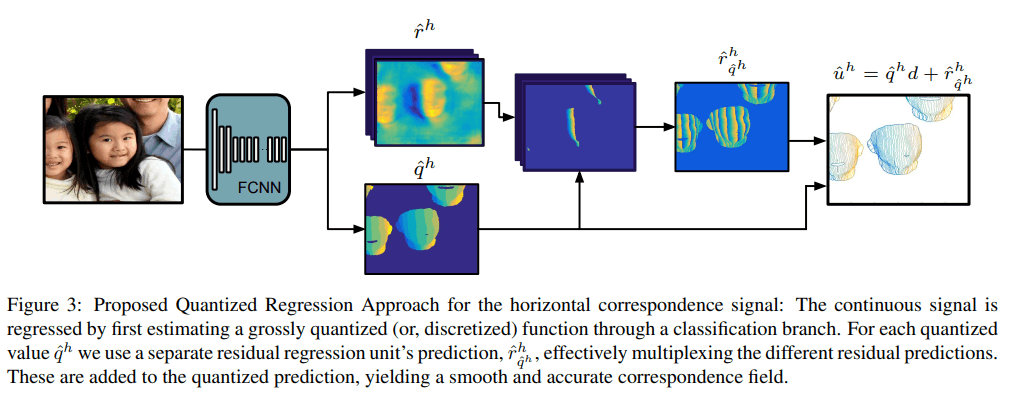
-[2] DenseReg https://arxiv.org/pdf/1612.01202.pdf
UV座標を予測するタスク。分類タスクとしてK binsでパート分けした後に、パートごとに残差を回帰して足し合わせる。
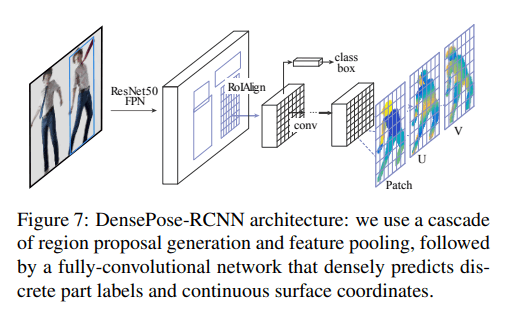
-[3] DensePose http://densepose.org/ https://arxiv.org/pdf/1802.00434.pdf
DenseRegは顔にフォーカスしていたが全身バージョン。K-binsのパート分けは体の部位に対応。
DenseRegはFCNNアーキテクチャだったが、Mask-RCNNアーキテクチャを採用。FCN(図中FCNN)はオブジェクトのスケールの変動に堅牢でない。
データセット(DensePose-COCO)の作成に貢献。
-[4] DensePose 3D https://arxiv.org/pdf/2109.00033v1.pdf
SMPLモデルなどのように3Dスキャンデータから変形パラメータを事前に獲得する必要がない。
関節のキーポイントを元に3D再構成をする研究よりもメッシュの表面のUV位置(Canonical Surface Map (CSM))を取得するDensePoseを利用したため精度が高い。
CSMを取得orアノテーションを用いて3D再構成をするため、DensePoseとDensePose3Dを別々に訓練できるはず。また、見た目に対して堅牢になる。``Since DP3D does not use images directly but only the DensePose annotations or predictions, it is robust to changes in the object appearance statistics,
which makes it suitable for transfer learning.''
reconstructionしたモデルのDenseMapとの損失を計算する。(reconstruct loss)
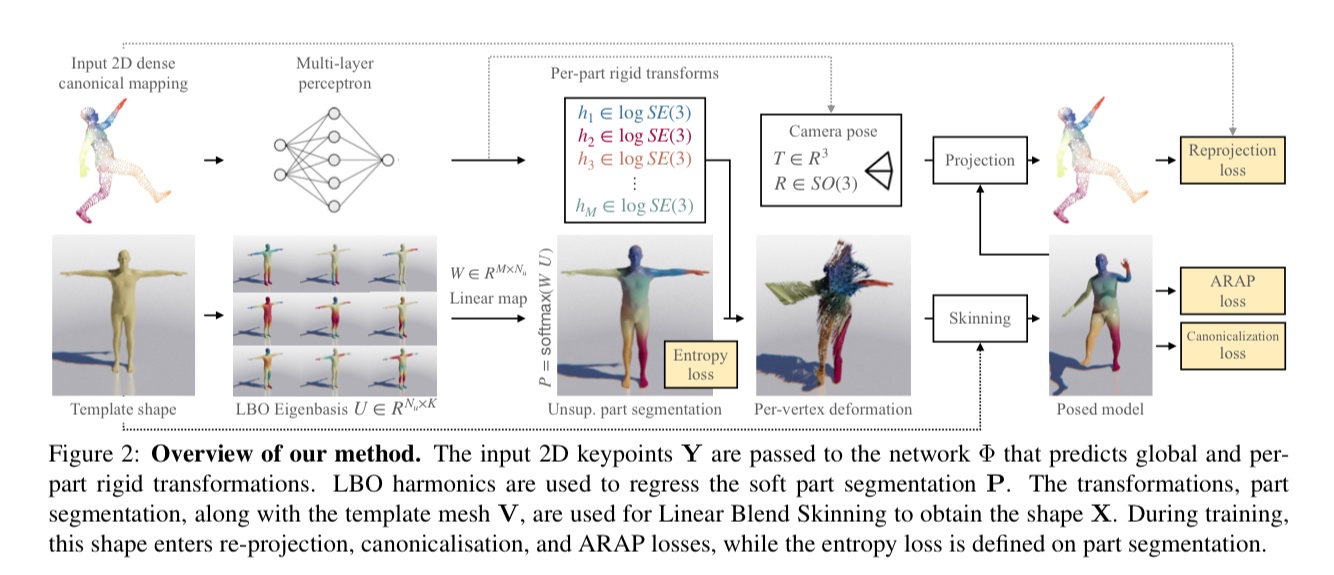
パーツ分けされた剛体単位内で頂点を移動することと、スムーズな変形をすることなどにより非現実的な変形を防ぐ。詳細は論文参照。
入力画像内で、template meshの頂点V_kに対応するCSMの頂点の座標y_kを取得する。occulusionで見えない頂点はZ=(z_k)^(K)_(k=1)∈{0, 1}^Kで定義。これがキーポイントになる。
考察
パーツ分けを10個から増やせば詳細に回帰が可能になるかもしれない。
non-rigidではなくrigid manner
テンプレートシェイプのプロポーションを変形することはできない。
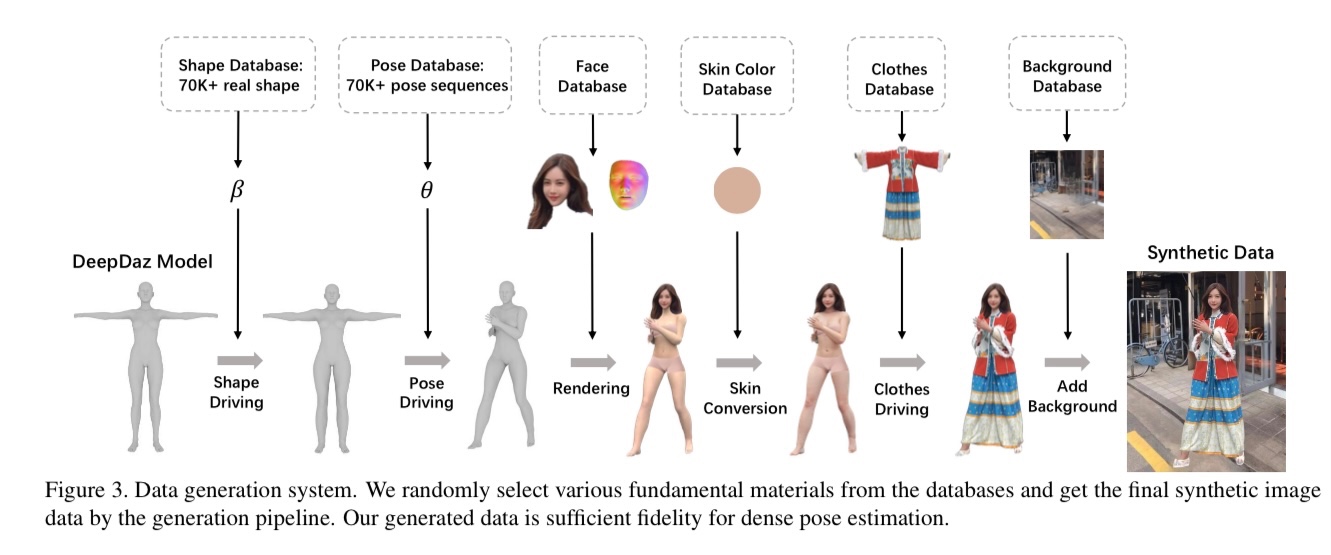
-[5] UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model https://arxiv.org/pdf/2110.15267.pdf
ハイポリゴンの3Dモデルによる合成された画像と対応する高密度なCSMのアノテーションのデータセット。
-[6] Slim DensePose: Thrifty Learning from Sparse Annotations and Motion Cues https://arxiv.org/pdf/1906.05706.pdf
DensePoseのアノテーションを削減するための研究。
動画のフレーム間のmotion cueから新たなアノテーションを生成。
-[7] Transferring Dense Pose to Proximal Animal Classes https://arxiv.org/pdf/2003.00080.pdf
動物のCSMをできるだけ教師なしで学習する手法の提案。既存のモデルを未知の動物に適用する方法を調査する。論文では、すでに人間や特定の動物につけられたアノテーションを活用する。実験として人間と近い、チンパンジーに拡張。
転移学習で拡張したDensePoseを教師ネットワークとしてアノテーションを収集しDensePoseの自己教師学習をする。学習済みのDensePoseモデルの調整は、チンパンジーの3Dモデルを用意しSemantic alignment=収集したアノテーションをSMPLモデル(DensePoseに使用)にリマッピングするすることで行う。continuous semantic descriptorを使用。
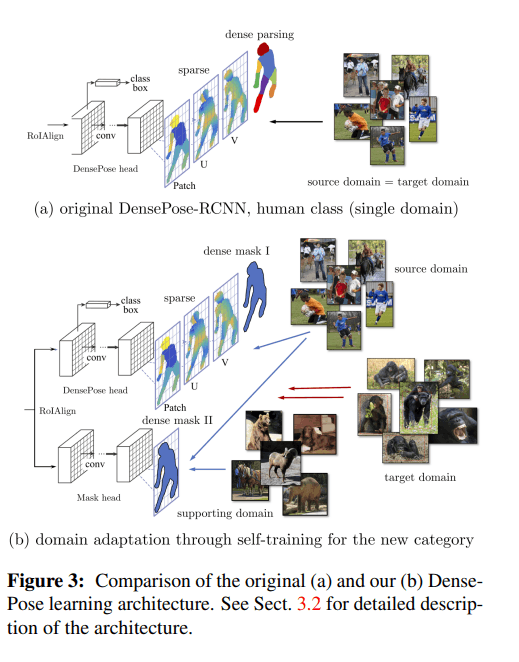
アーキテクチャは、DensePose headとMask R-CNN headを含む(下図)。下の画像のdense parsingやdense maskはinstance segmentationのためのもの。
Mask R-CNN headではクラスに依存しない学習することでより多くの情報が得られ、最終的なチンパンジーのクラスへの汎化性能が上がる。
DensePose headとMask R-CNN headは両方ともセグメンテーションコンポーネントを含むが、前者は人間のドメインに対して学習し、後者はCOCOデータセットの一般的なセグメンテーションを学習する。RoIAlignの前のback boneであるResNetなどのネットワークがこのマルチタスクの学習によって転移学習を促す学習がされるのでは。
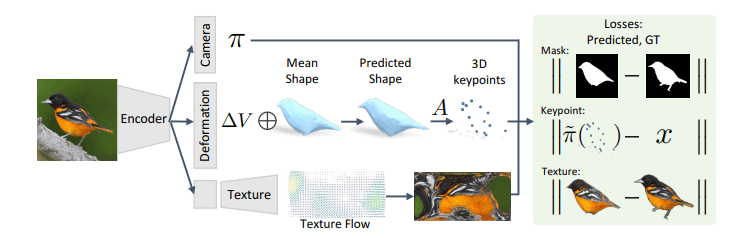
-[8] Learning Category-Specific Mesh Reconstruction from Image Collections https://arxiv.org/pdf/1803.07549.pdf
単視点画像からdeformable 3D meshを学習する。平均形状の構築と、変形のパラメータ化。キーポイントとマスクのアノテーションが必要。
-[9] Functional Maps: A Flexible Representation of Maps Between Shapes https://people.csail.mit.edu/jsolomon/assets/fmaps.pdf
shape上で定義された関数による基底を用いたshape matching. ``by generalizing the notion of a map to include pairings of functions instead of points, map inference can be phrased as a linear system of equations''
-[x] Continuous Surface Embeddings https://proceedings.neurips.cc/paper_files/paper/2020/file/c81e728d9d4c2f636f067f89cc14862c-Paper.pdf
画像上の画素と3Dshape上の頂点をそれぞれ潜在ベクトルCSE(Continuous Surface Embeddings)にエンコードする
式(4)は画像I上のxがメッシュS上の頂点kに対応する確率p(softmax-like)のクロスエントロピー(式(3))をジオメトリックに拡張した式。log pの平均を取っているのがクロスエントロピー。

頂点の対応やパーツごとの対応を用いて画像とメッシュの関係を学習すると、異なるメッシュ間でマッピングの知識を共有できないためにfunctional mapsを活用する。これによってジオメトリックな情報を考慮できる。
これらによって、少ないアノテーションデータから多クラスのCSE(CSM)を学習できる。
多クラスのテンプレートメッシュベースのアノテーションが必要。
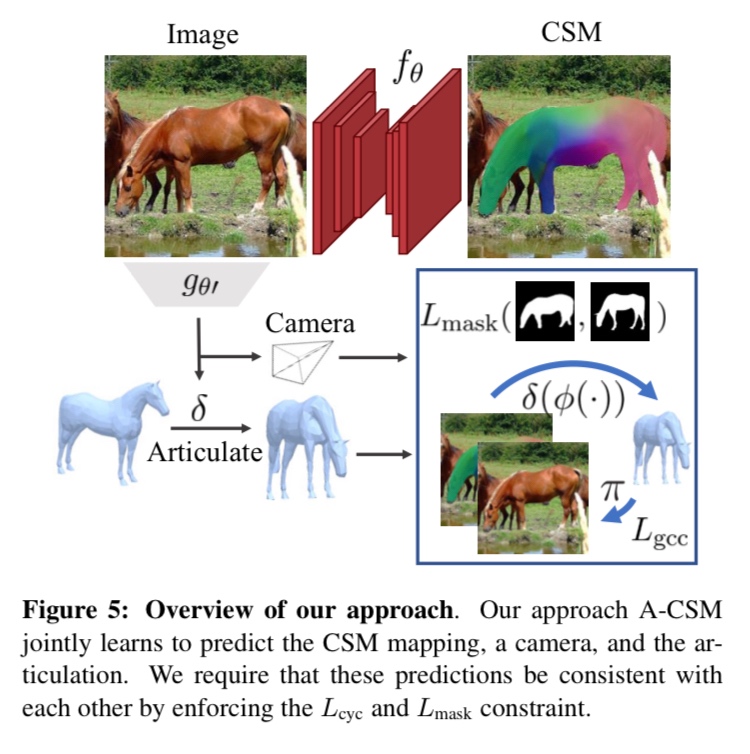
-[10] Articulation-aware Canonical Surface Mapping https://arxiv.org/pdf/2004.00614.pdf
foreground maskのみから、様々なクラスのCSMとポーズの学習をする。2Dの画素を3DテンプレートにマッピングするCSMの予測タスクと、3Dテンプレートのポーズを変えて2D画像に合わせるタスクは幾何学的に関連しており、相乗効果を生む。
テンプレートベース。
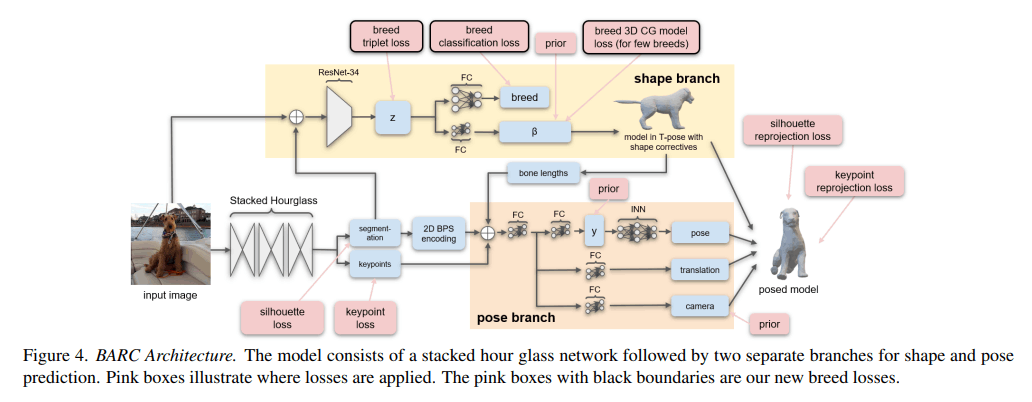
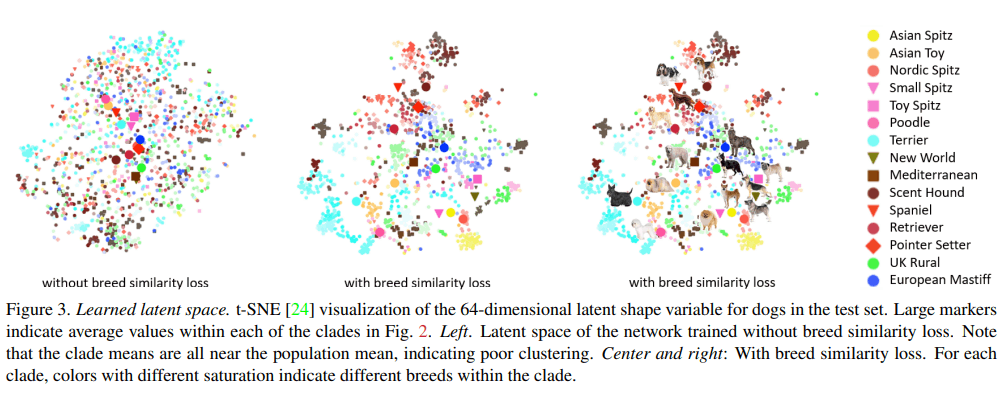
-[11] BARC: Learning to Regress 3D Dog Shape from Images by Exploiting Breed Information https://arxiv.org/pdf/2203.15536.pdf
犬種ごとの3Dテンプレートと他の動物の3Dテンプレートの平均の形状からPCAでパラメータを抽出。

犬種のクラス分類ブランチのclassification lossとtriplet lossによっての犬種の情報が特徴づけられた潜在特徴空間を作ることができ、形状のパラメータの決定に寄与する。
-[ ] Dense-Pose2SMPL https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9831448
DensePoseのmapからSMPLモデルのパラメータを回帰して再投影したlossからポーズをiterative optimizationする。lossに工夫がある。
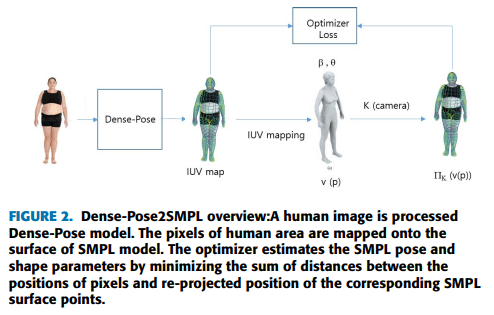
カメラ投影の曖昧さ回避のために身長は統一とみなす。
mapを元に学習するためSMPLifyで用いたjoint errorをpixel-wise re-projection errorに改良している。

-[ ] SMPLicit https://arxiv.org/pdf/2103.06871.pdf
-[ ] Learning Free-Form Deformation for 3D Face Reconstruction from In-The-Wild Images https://arxiv.org/pdf/2105.14857.pdf
-[ ] Transfer Learning for Pose Estimation of Illustrated Characters https://arxiv.org/pdf/2108.01819v3.pdf
-[ ] Dense feature pyramid network for cartoon dog parsing https://link.springer.com/content/pdf/10.1007/s00371-020-01887-5.pdf
メモ
[11]のtriplet lossの考え方は使える。
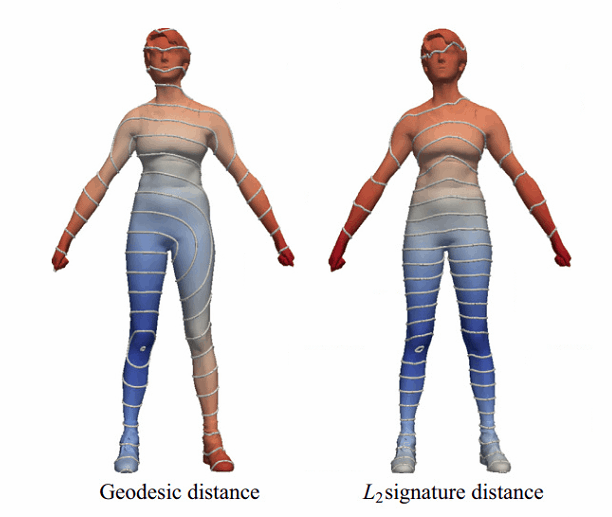
Geodesic distanceは使える。
[7]の転移学習の仕組みで違うプロポーションの体に拡張できそう。
3D構造に従った画像(正画像)とhuman errorのある生画像を学習する方法を考える。
正画像の分布からPCAのパラメータを推定した後に、reprojectionして、正画像の中には納まらないようなイレギュラーなパラメータを探す。
正画像と生画像に対するCSMを敵対性lossで確率化する。
抽象化した立体の変形