読んだ論文をまとめる習慣が三日坊主で終わっていたので再開
Skeleton-Aware Networks for Deep Motion Retargeting https://deepmotionediting.github.io/retargeting
モーションをプロポーションの違うモデルのスケルトンにリターゲティングするやつ。Githubにコードあり。
Sketch2Poseの論文に書いてあったRetargetingモデル。
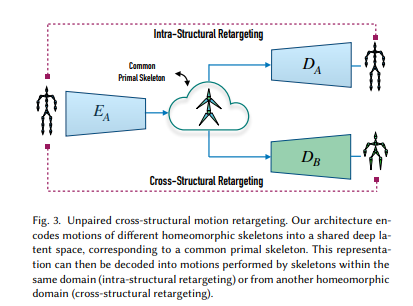
アーキテクチャの画像を見ると、SkeltonごとにGANのモデルをトレーニングする必要があり、そのモデル間でcross stracturalなretargetingもできるということなので万能ではない。
E:Encoder、D:Decoder、C:Discriminator
S:initial pose、Q:Joint rotations
だから結局対となるデータセットが必要。
推論時にはinputのS,QとターゲットのSを使う


Poolingによって最小単位の構造にすることで構造が違っても使えるようになるらしい。
Visual Question Answering における視線情報を用いた質問の曖昧性解消 https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/E1-1.pdf
視線情報を入れるためにAdapterを追加し、CLIPで注目領域をエンコードしたベクトルを統合するアーキテクチャらしい
https://ai-scholar.tech/articles/object-detection/patchcore 異常検知手法のPatchCoreの解説
informative drawings で、ラフスケッチを描く | cedro-blog http://cedro3.com/ai/informative-drawings/
Joint Audio and Speech Understanding https://arxiv.org/html/2309.14405v3
音声とLLMを結び付けたモデル 音声認識モデルのWhisperでエンコードしたembeddingをどうやってLLMに結びつけるのか知りたくて読んだ。
データセットを作ったらしい。


画像出典:https://deim2024-tutorial-public.s3.ap-northeast-1.amazonaws.com/TU-B-1_LLMと音声.pdf
以下DINOv2など