Sketch2Poseの被引用から。
SketchBodyNet: A Sketch-Driven Multi-faceted Decoder Network for 3D Human Reconstruction
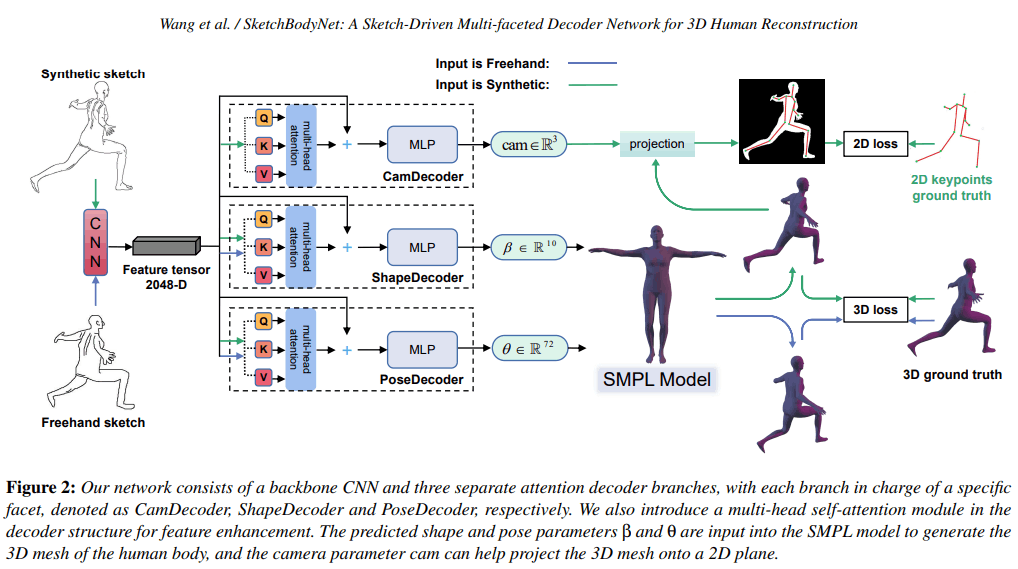
フリーハンドスケッチからの3Dポーズとシェイプの再構成をするmulti-faceted decoderの提案。
ネットワークは、バックボーンと3つの別々のアテンションデコーダーブランチから成る。これらのmulti-head self-attentionモジュールから抽出された特徴はMLPによって処理され3D最高性が行われる。
これらの3つのモジュールはそれぞれカメラ、シェイプ、ポーズの予測をする。SMPLに基づく。
アノテーションは3Dモデルデータ。
ポイント
カメラ、シェイプ、ポーズを共有のネットワークではなくブランチに分けることで相互的な悪影響を防ぐことができる。
3Dから合成されたデータとリアルデータの混合データを初期の学習では使い、段階的にリアルデータだけにするという段階的な学習を行う。step-wise refinement training (SRT)
合成データの場合は2DキーポイントのGTを使うがリアルデータでは使わない。