アーキテクチャの話だ。Zennでやれ、と思うかもしれないが俺は私見を、ポエムを書きたいのだ。だからしずかなインターネットで書くのだ。
ちょっと長い前説
CQRS+ESという言葉は知っているだろうか? Command Query Responsibility SegregationとEvent Sourcingだ。ハイパー平たく言うと「メリットいろいろあるから書き込み側と読み込み側を別のシステムにしましょうね。で、それやると自然とイベント発生ログをマスターデータにする仕組みになるよ」という話しだ。
以下のような図でよく説明される
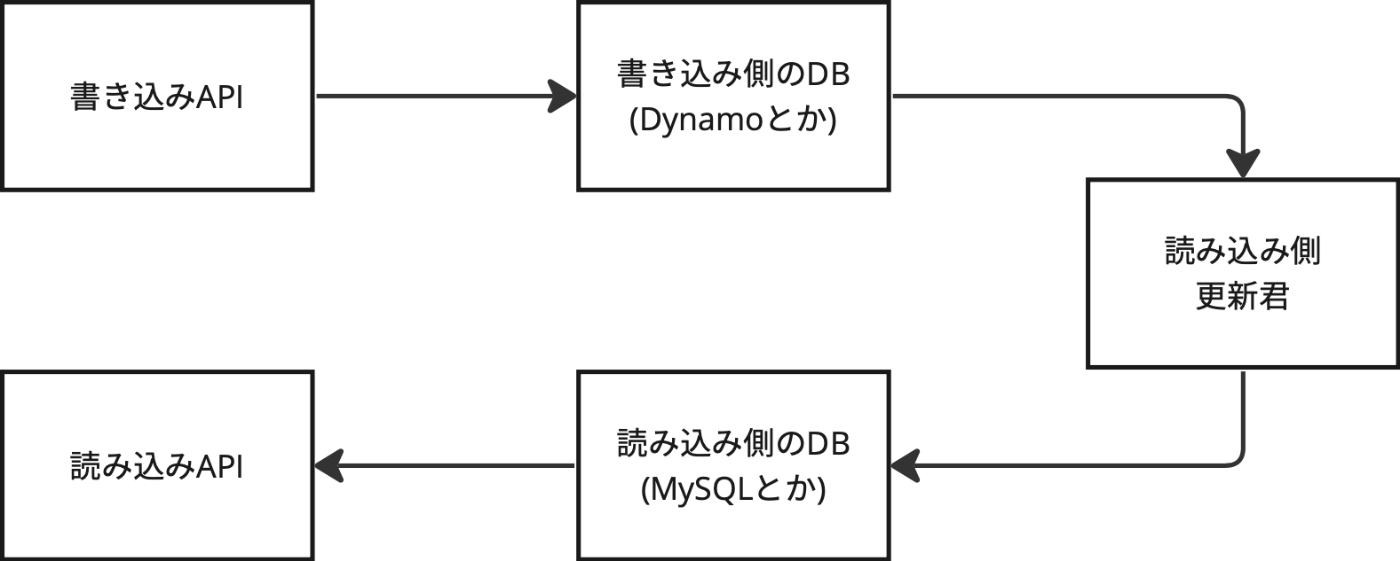
少なくとも自分はこの言葉を2015年に発売された実践ドメイン駆動設計で知った。この本はIDDD本と呼ばれDDDを学ぶ者にとっては重要な本だ。だからCQRS+ESはDDDと紐付けて語られる事が多いと思う(実際組み合わせて使う物だとは思うけど)
図を見ただけだと”なんでそんな面倒くさいことするの!?" と思われるだろう。メリットはいろいろある。
詳細は各で調べていただきたいが、一番大きいのは "書き込み側は安全に行きたいし、DDDとかを駆使してかっちりと作り込みましょう、でもリード側は堅いこと言わずに好きな方法でやってよいよ?手っ取り早くやりたいでしょ? " というのが可能なところだろう。パフォーマンスや耐障害性を突き詰めるならでかい。
CQRSとESは別の話なのだが、書き込み側から読み込み側には「こんな変更があったから更新しといてね!」というイベントがどのみち飛ぶので、それならイベントをマスターデータにする(つまりはイベントをソースにする=イベントソーシング)のが自然、という流れでセットになっていることが多い。
…で、やらんよね?こんな大変なこと。必要になる場面がありそうなのは分かるけど。
でも、わかったんですよ
まずはシステムの始まりはこうだよね

で、運良くサービスが成長してトラフィックが増えたとしてデータベースがネックになりがちになって、強いインスタンスにしても間に合わなくなってCacheサーバとかを持ち出すことになってこうなるとおもう。
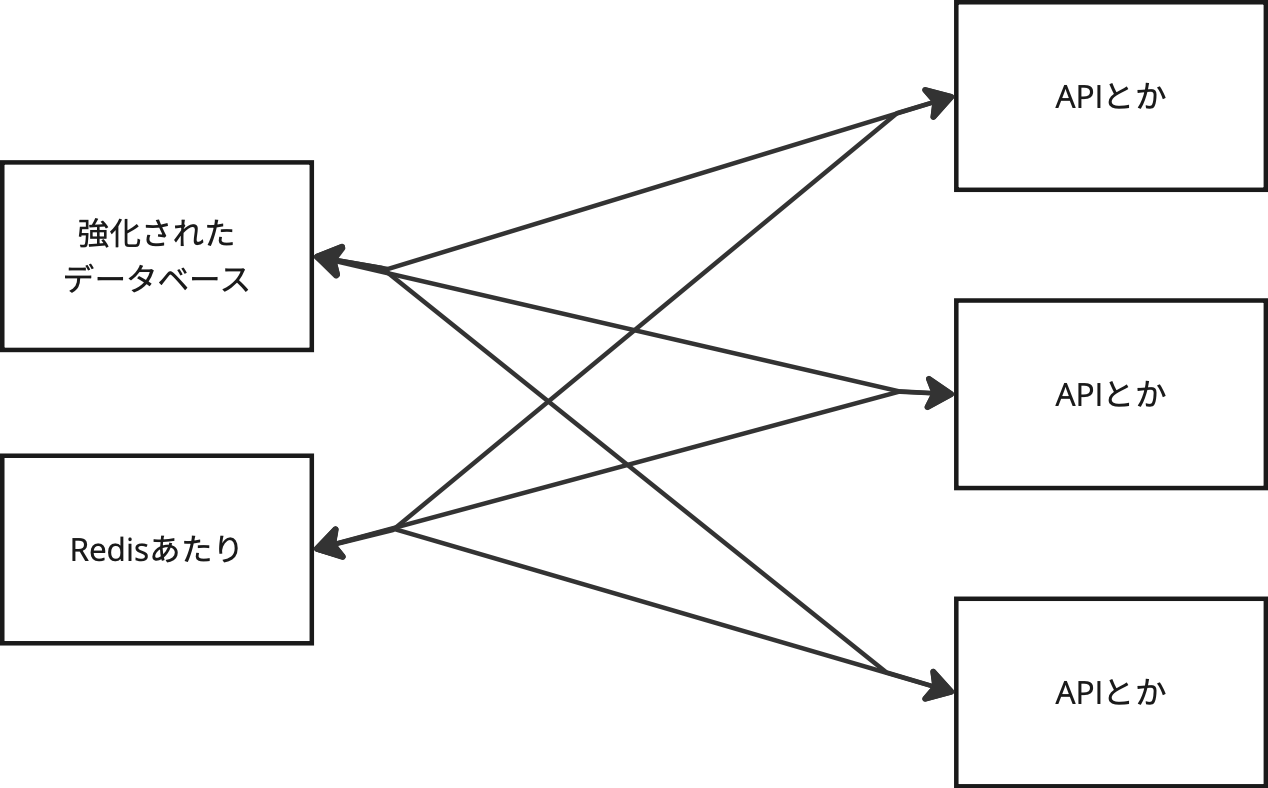
自分が手がけてきたニコ生もGANMA!もSUGARも基本はこれ。SUGARとかは99.9%のCacheヒット率で、データベースはPlanetScaleを使っているが一度もトラフィック課金が発生したことがない。(トラフィックが多くない、ということもあるけど)。だがしかし、これは今ではもうやってはいけないアーキテクチャだと考えている。
実装的には基本的には次のようになる
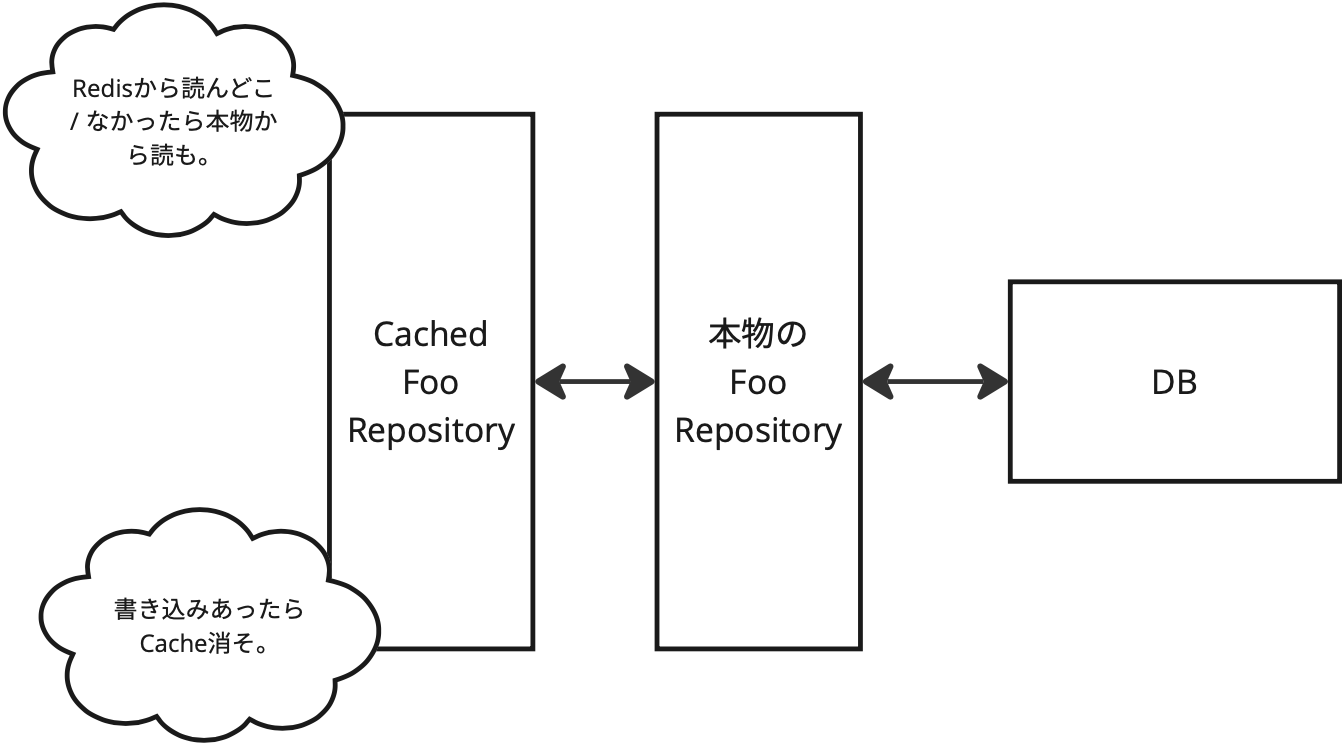
簡単には書いているが "Cacheを消す" というのが異常に面倒くさい。事故らずにやるのはなかなか難しい。そもそもこれはデータベースとRedisでデータを二重管理していることになる。やるしかないときはあるとはいえ馬鹿らしい。
では、次のような構造は有りだろうか…?
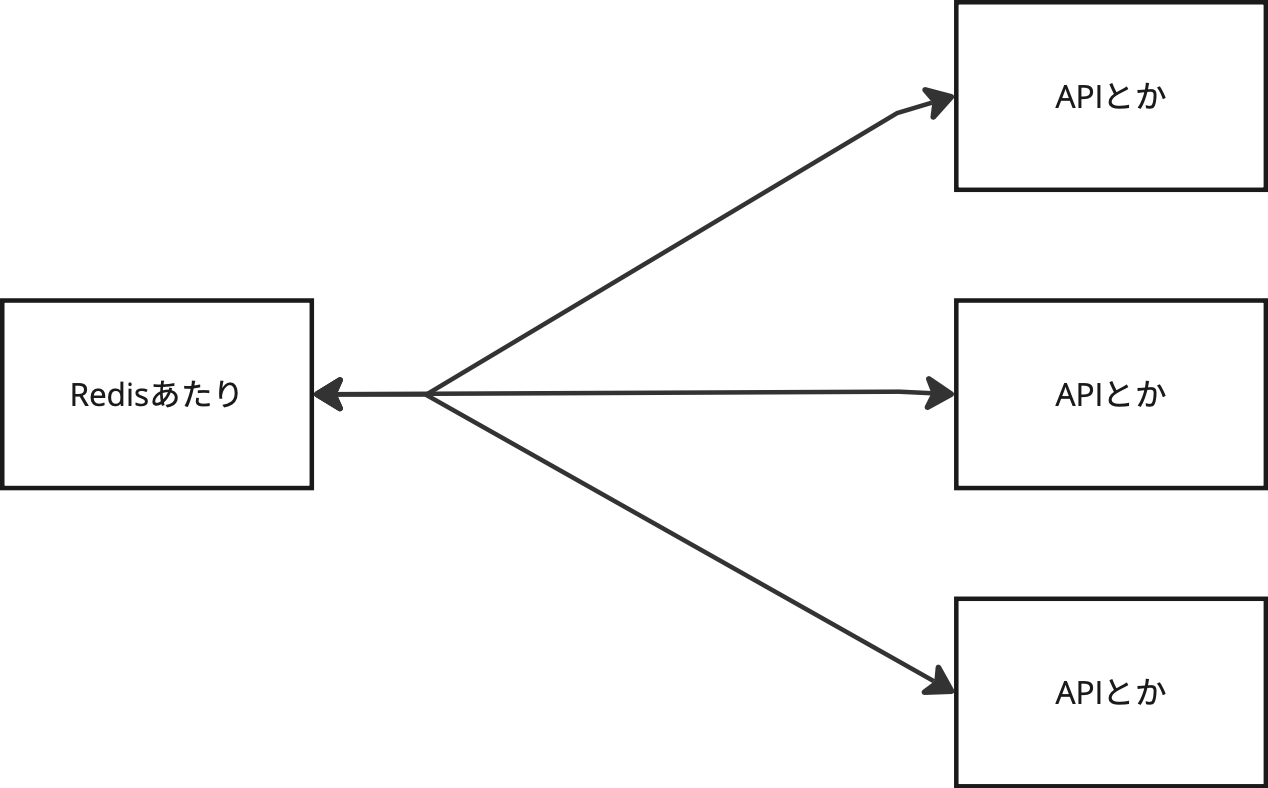
…ないない
まずRedisはただのKVSであって、いや結構進化しててトランザクションもあるしJSONも扱えるし全文検索もあったりするけどそれでもKVSであってね?検索とかはかなり辛いよ?
めっちゃデータ非正規化しまくったり、補助でAlgoliaとか使ったりすれば渡れるとは思うけど?
とは思うだろう。そして思ったんだ。
…CQRS+ESだったらリード側をRedisだけにしても怖くないんじゃないかって
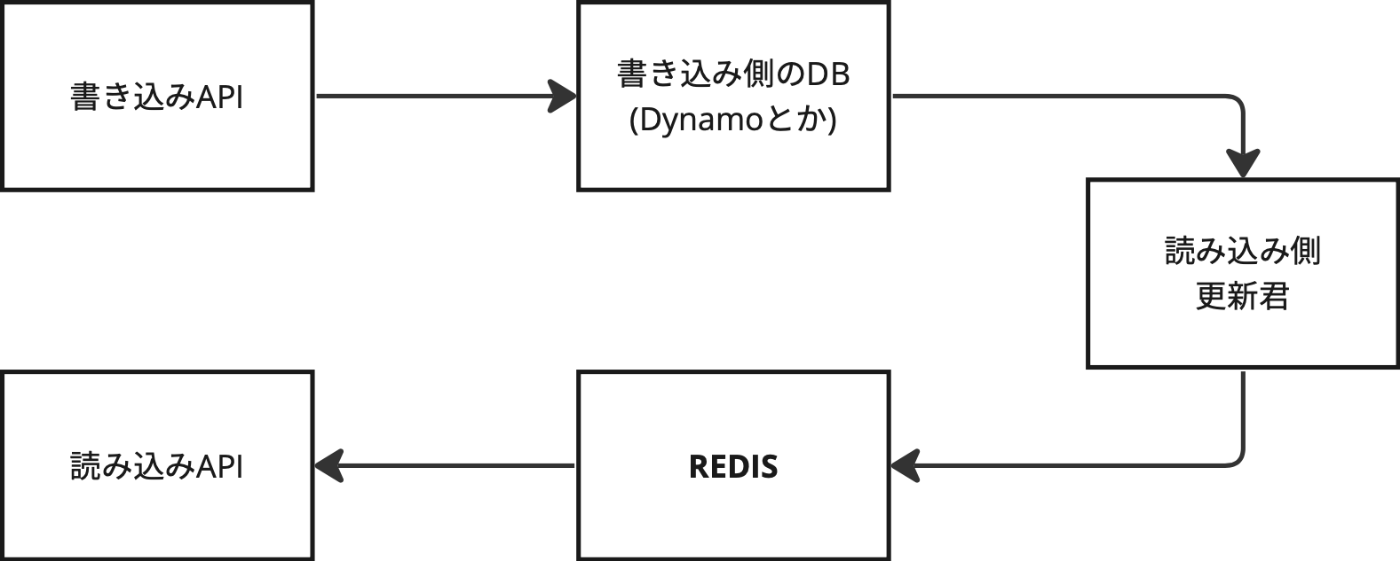
※補助でたぶんAlgoloaかtypesenseも使います
絶対にやってはいけないとおもう
まず一般的にオススメするアーキテクチャはこうだ

最近のデータベースは凄い。NewSQLとも呼ばれているやつらは悪い使い方をしなければ読み書き両方ともいくらでもスケールしてくれる。この前発表されたAmazon Aurora Limitless Databaseなんかは "Amazon Aurora クラスターを 1 秒あたり数百万件の書き込みトランザクションにスケールし、ペタバイト単位のデータを管理できるようになります" だそうだ。
大体の案件ではこれらの持ち味を生かして開発していくだけで問題ないはずだ。気がついたら二桁万円、下手すれば三桁万円毎月吸われてた、みたいなことになりやすいのが最大の欠点だが安定とスケールを最初に手に入れられるのは大きい。
冷静に考えてくれ。月に100万かかったとしても1〜2人分の人件費でしかないんだぞ。節約のための工事を後回し、かつ簡単にする権利と考えれば高くはないと思う。
しかし…
しかし…残念ながら俺の資金はそれほど潤沢ではない。別のエントリーでも話したがServerlessとも相性が悪い企画を開発している。
このCQRS+ESを採用し、リード側をRedisだけにする、というのは企画と財政状況に、めちゃくちゃ合っている気がした。
だから俺は自力でCQRS+ESの基盤を作ったのだ。
そのためにどのような実装をやったのか紹介する。真似してはいけないとわかるはずだ
※ゼロから基盤を作ることを真似してはいけないのであって、CQRS+ESは要件が合えば検討すべき
言語はScala3を採用した。
ZIOを使う必要があったからだ。ZIOはなんと説明するのがよいのか分からないが、語弊を恐れずに言えば、なにもかもが
async func doSomething(container:DIContainer, param:...):Either[エラーの型, 成功の時の型]
になった世界だ。文字を表示するのだって全部非同期だしDIコンテナを求めるしエラーの型(Nothing)と成功の時の型(Void)みたいなものだ。
ぎょっとするかもしれないがCQRS+ESの"読み込み側更新君(ReadModelUpdater - 以下RMU)"にはStream処理が必要なのだ。ZIOを使えばStreamは扱えるしエラーハンドルも自然に行える。
EventSourcing側はかとじゅんのライブラリを採用
かとじゅん(j5ik2o)はかつての同僚だ。かとじゅんのこれを使わせて頂いた。以下の改造を行った
RMUが死んでも途中から再開できるように、イベントを途中から取得できるように改造
合わせて時間を前後できないように改造
Jacksonではなくjsoniter-scalaを使うように改造
リード側にイベントを伝えるのはDynamoDB Stream + Lambdaでやるのが普通だが、RedisのPub/Subを使ってリード側にイベントを通知するように
Jedisのラッパーを自作
RMU側はパーテーションキー毎にfiberを立ち上げ以下の動作をするようにした
起動したらRedisにメモってある最終処理時間から最新までイベントを全部よんで更新する
Redisのトランザクション機能を使って、複数RMUが動いていてもパーテーションキー毎に一つしか勝ち残れないようにする(トランザクション失敗したら一定時間止まる。CSMA/CDみたいな。
その後はStreamを駆使してRedisのSubscribeでイベントが飛び込んできたら処理をする
データは管理しやすいようにRedisのJSON構造を多用する
しかしScalaのRedisクライアントでTransactionやPub/SubやJson読み書きにちゃんと対応したものはない。しかししかしScalaはJavaのライブラリを使える。だからJedisをラップしてZIOからRedisを上手く扱えるコードを沢山書いた。
なおRMUは根底から自作するものではない。自分の知る限りではZIOかAkkaを使わないとやってられない。既存のもの(かとじゅん作)に頼るべきだ。
C#だとこんなのもリリースされたみたい
そして。
時間が貴重だというのに1ヶ月も基盤作りに時間をかけてしまった
楽しかったが、これをやった甲斐がでるかはわからない。たぶんバグは多く不安定だろうし、トラフィックも殆どでなくて残念だったね、で終わる可能性のほうが高い、しかしやらねばならなかった。
一応、CQRS+ESでよかったぜ!と言える未来を勝ち取るつもりだ。